Automatic Data Cleansing and Preparation
What is it?
- When using webpages as documentation for the KnowledgeBase, nuisance information such as banners and cookies will deteriorate information relevant to the users organization. The Automatic Data Cleansing feature of NeuralSeek will automatically cleanse the web pages that were scraped, exposing information pertinent to the organization, at the users own pace.
Why is it important?
- Condensing and focusing the information, while removing useless wording returned by the KnowledgeBase is critical to high quality answer generation. Most web content is not great at directly answering questions because of the amount of nuisance webpage language that gets extracted with the core content.
How does it work?
- NeuralSeek will identify documents in the KnowledgeBase that come from webscrapes. NeuralSeek will then run its own algorithm against the full webpage HTML to extract just the core content and remove as much of the extraneous information as possible.
Caching
What is it?
- NeuralSeek uses caching strategy in two areas (Corporate KnowledgeBase and Answer) to enhance performance and reduce computational cost during its operation.
Why is it important?
- Caching frequently returned answers saves both time and computation cost to run virtual agents, as it reduces NeuralSeek having to generate responses repeatedly, especially on the more frequently asked questions or seldom updated answers.
How does it work?
- The first part is when NeuralSeek searches through the corporate knowledge base to obtain the original information. You can set the cache duration of such responses to be cached, so that the original information’s retrieval time can be reduced.
- NeuralSeek then utilizes two types of caches for both your edited answers and generated answers that can serve cached answers to user questions in order to speed up response times and produce more consistent results.
Corporate KnowledgeBase Cache
When NeuralSeek accesses the Corporate KnowledgeBase, it processes the original data from it, cleanses its contents (e.g. removing unnecessary contents, filtering, deduplicating, etc.), compresses it, and prioritize the returned contents which is then processed with LLM (Large Language Model) to form the completed response, usually at the range of 8,000 ~ 9,000 characters. It then derives a hash value of that response window which acts as a check to later see if the original data is updated. This response is what actually gets cached within NeuralSeek, so that all the search, processing, and LLM-generated time is effectively saved when the same answer needs to be derived.
Under the Configure > Corporate KnowledgeBase Details section, user can set the duration of the cache measured in minutes to control how long these responses need to be cached.

Answer Cache
When the user asks a question to NeuralSeek, it tries to use the question to find the matching ‘intent’ of the question. And when the matching intent is discovered (usually via fuzzy matching), the provided answer, either normal or user edited, can then be cached.

Under the Configure > Intent Matching & Cache Configuration section, you can enable or disable the edited answer cache or normal answer cache, and set the following parameters to control how it works:

Each cache type (edited answer, normal) would have the answer threshold bar and edited answer match tolerance. You can adjust the threshold to control when the caching will start caching for the answer, depending on how many answers exist for a given user question. For example, if you set the threshold to 5, the caching will not start until there exist 5 or more different answers to the given question. Setting the threshold to 1 would let NeuralSeek start caching as soon as it sees at least a single answer exists. Setting the value to 0 will disable caching completely.
The matching method (Exact Match, Fuzzy Match, etc.) is the method you can specify to tell NeuralSeek on how to perform the intent matching on the question.
There is also a more advanced matching method of ‘Exact Match, exact conversational context’ on the normal answers that would try to find the match if the consecutive conversation (e.g. one and the one after) both have the matching result, so that the match could be more correct in terms of how the conversation flow is occurring.
In terms of the edited answers, this ‘conversational context’ matching is not provided given that the edited answers should be more concise and based on a more substantial ground and thus should not rely on the conversational context.
Detecting changes in the original source
In order to make sure the cached answers retain the authenticity, every cached answers are fed into a hashing algorithm to generate a unique hash key, which is then compared with the original source to detect whether the original source has been altered or not.
If the hash keys do not match, NeuralSeek will notify users that the answers are not up-to-date with what’s found in the KnowledgeBase. This would happen when a particular answer is being used during the Seek time, so that the answer would be kept in check with the original.

Users can then take a look at the outdated answer, and can either delete and reload it, or edit it and then mark it as current, so that NeuralSeek will be able to check it off from its outdated list.

One other way the answer would be checked is when NeuralSeek is handling round trip logging. During that time, NeuralSeek would check which answers are getting frequently returned and also perform asynchronous checks with the KnowledgeBase to make sure they are up-to-date.
How do we know the answers are coming from cache?
You can check whether your query matched and returned the cached answer in the Seek tab. For example, this is an example of the answer returned from the cache.
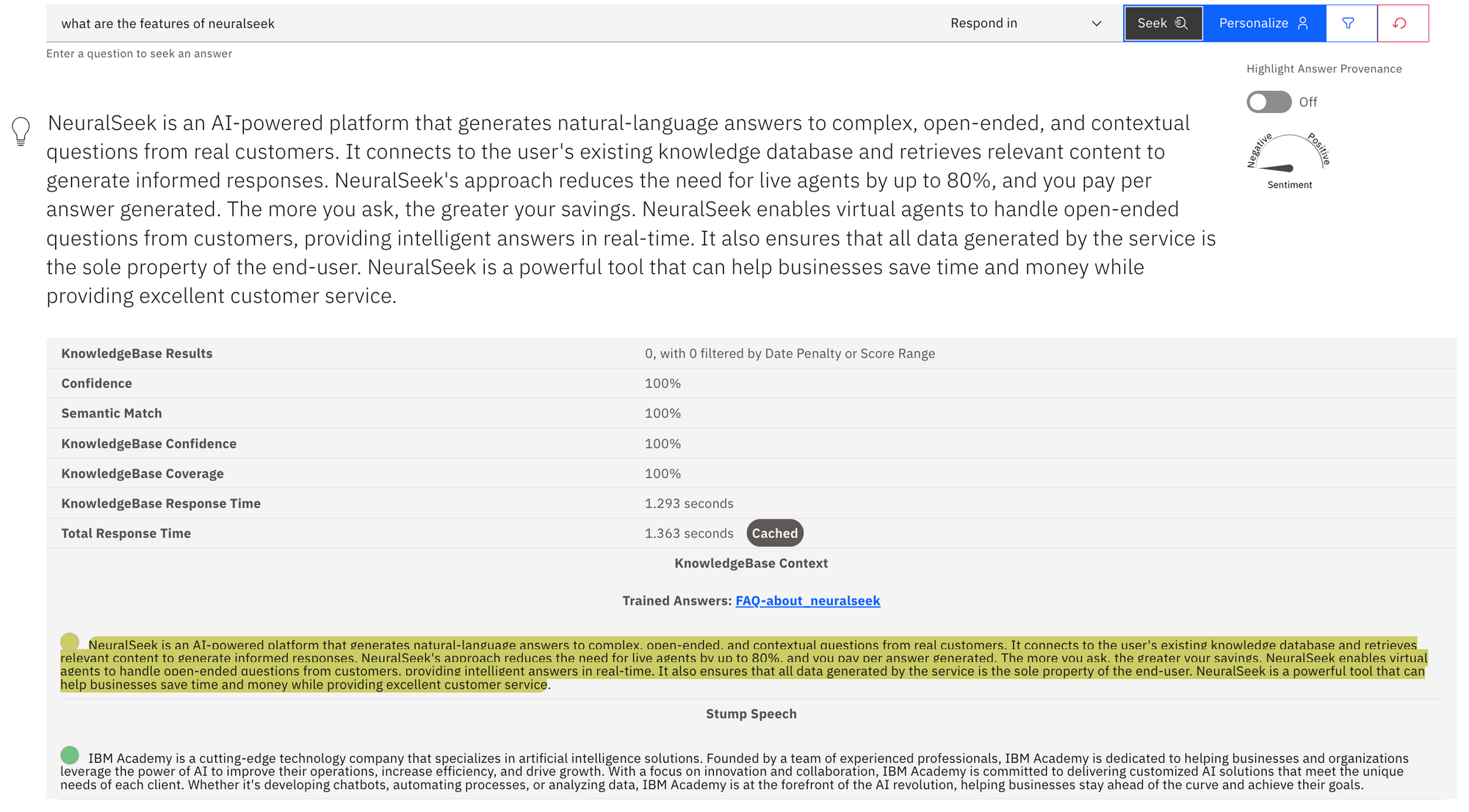
Next to the Total Response Time, you will see a label Cached which indicates that the answer came straight from the cache.
Content Analytics
What is it?
- NeuralSeek incorporates content analytics as a built-in feature, eliminating the need for additional code. With Content Analytics in NeuralSeek, users can effortlessly gather information about what users are searching for, assess the extent of documentation available on those topics, and evaluate documentation efficiency in addressing user queries.
Why is it important?
- Content Analytics are a powerful feature that enable insight on the performance of your corporate documentation. You can gain insights on where content is excellent, underperforming, nonexistent or seldom used - and inform the groups responsible for creating or updating that information on how better to allocate their time.
How does it work?
Two main scores are returned when a user asks a question to NeuralSeek:
- Coverage Score: This score represents the number of documents or sections of documents that discuss the subject area(s) of a question from NeuralSeek.
- Confidence Score: The confidence score represents the likelihood that the information found in the KnowledgeBase of NeuralSeek and presented as a response is correct. This probability is given as a percentage. Low scoring questions with low coverage scores tend to mean there is little or no documentation on the subject. Low scoring questions with high coverage tends to mean there are conflicting source documents.