PII Detection
What is it?
- NeuralSeek features an advanced Personal Identifiable Information (PII) detection routine that automatically identifies any PII within user inputs. It allows users to flag, mask, hide, or delete the detected PII.
Why is it important?
- Users can maintain a secure environment while providing accurate responses to user queries, ensuring compliance with data privacy regulations and protecting sensitive information.
How does it work?
- Common and well known PII detection is enabled by default in NeuralSeek. When you enter a PII information, for example, when you enter a credit card number in Seek:

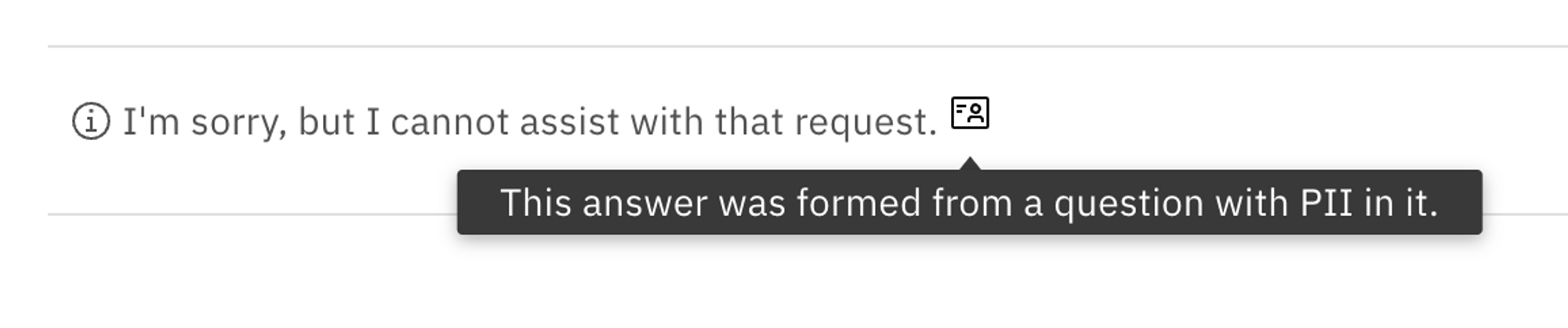
In NeuralSeek, the question above will be logged and flagged as containing PII information and warns user about a potential risk.
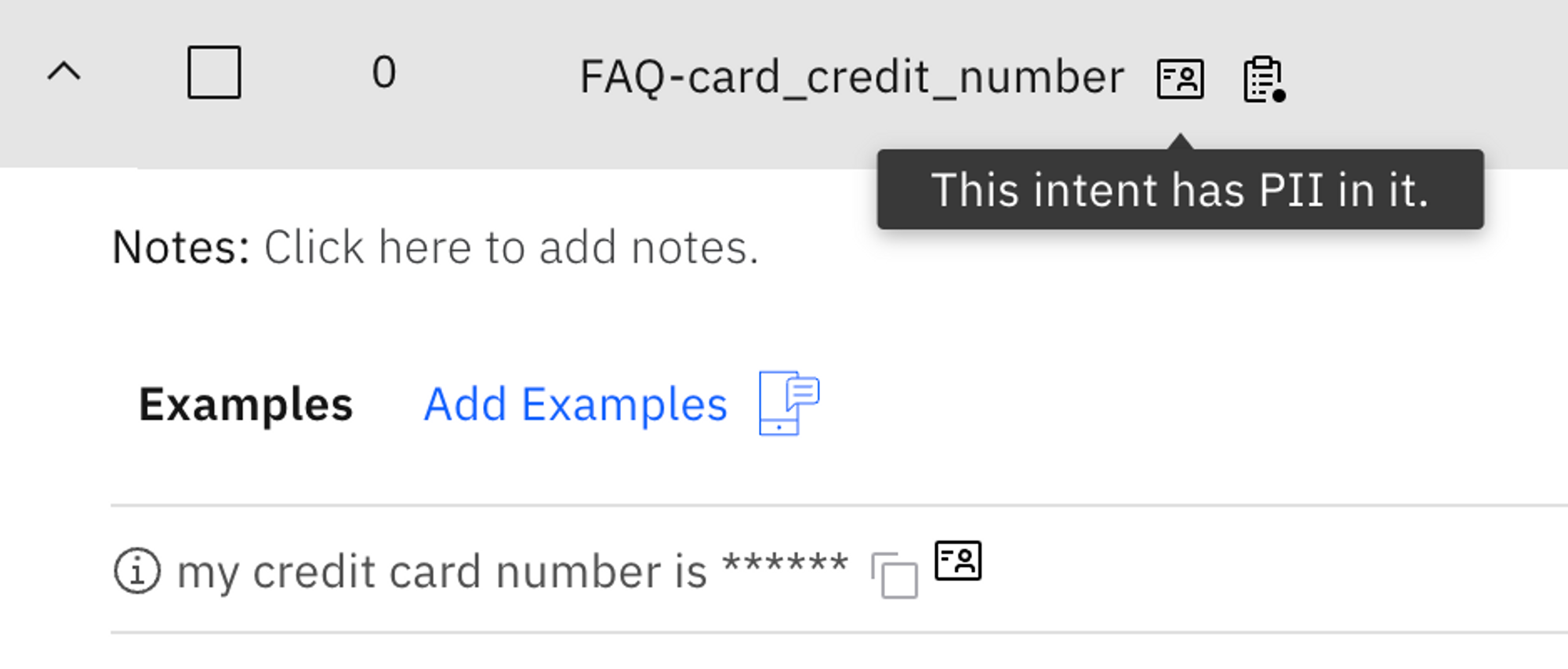
The credit card number is also masked and removed, so that the data is protected from being viewed. The answers to these questions also indicate that they were generated from a question with PII in it, so that you can easily identify them.
Defining a specific PII
However, this is what NeuralSeek does against common PII patterns, and there may be a specific PII that you would like to hide for your specific business needs. If you want to help NeuralSeek better detect and process PII for that, you can configure it under Configure > Personal Identifiable Information (PII) Handling in the top menu:

How it works is based on an example sentence, and does not have to be an exact pattern or rules. For example, setting the example sentence as:
My name is Howard Yoo and my blood type is O, and I live in Chicago.
For each PII element in that sentence, you can define the PII elements in that sentence delimited by comma as such:
Howard Yoo, 0
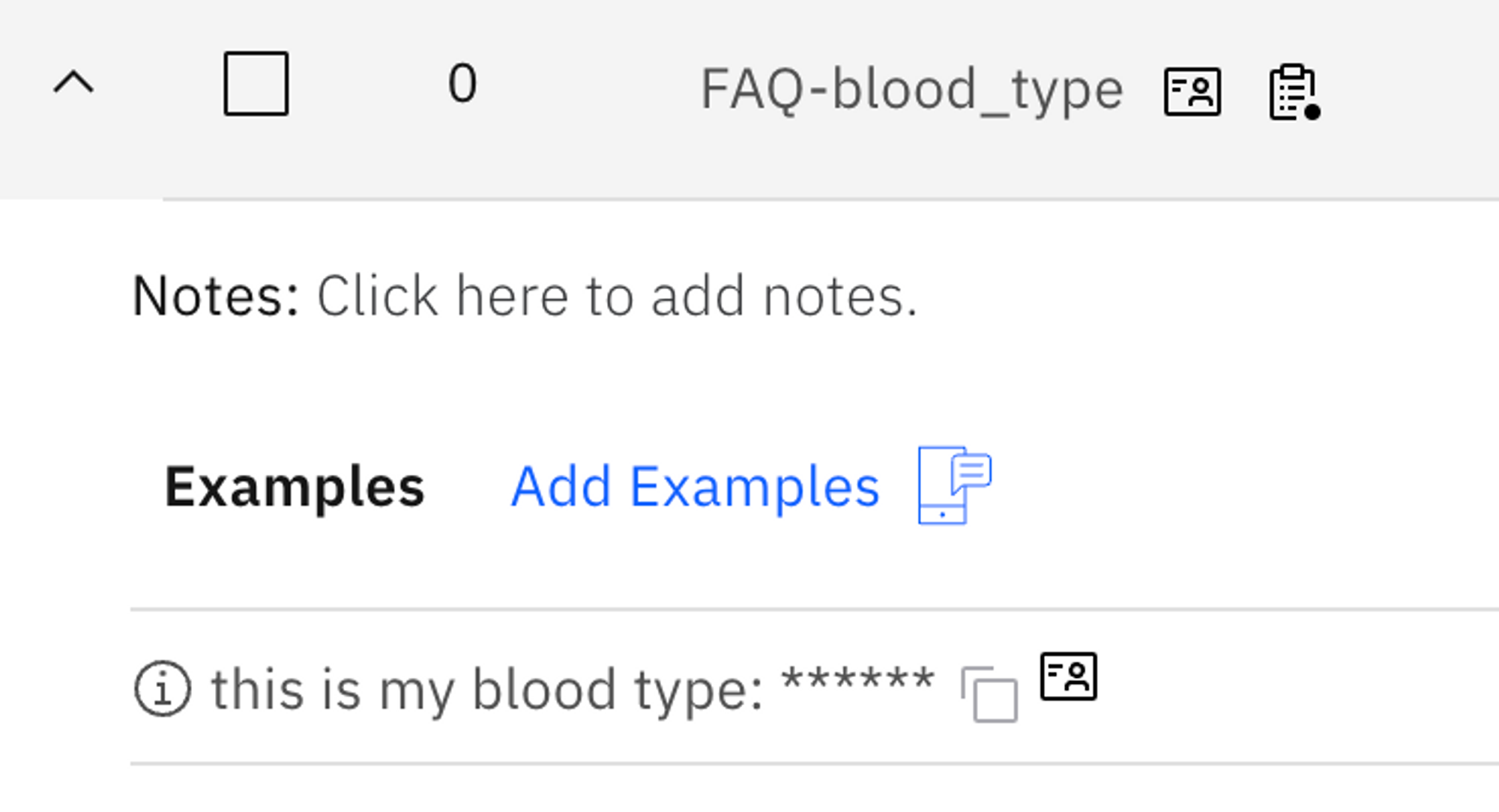
So, next time, when somebody enters a PII matching the example as such:
This is my blood type: A
NeuralSeek now detects that and masks the blood type that the user provided from being exposed:
Ignoring certain PII
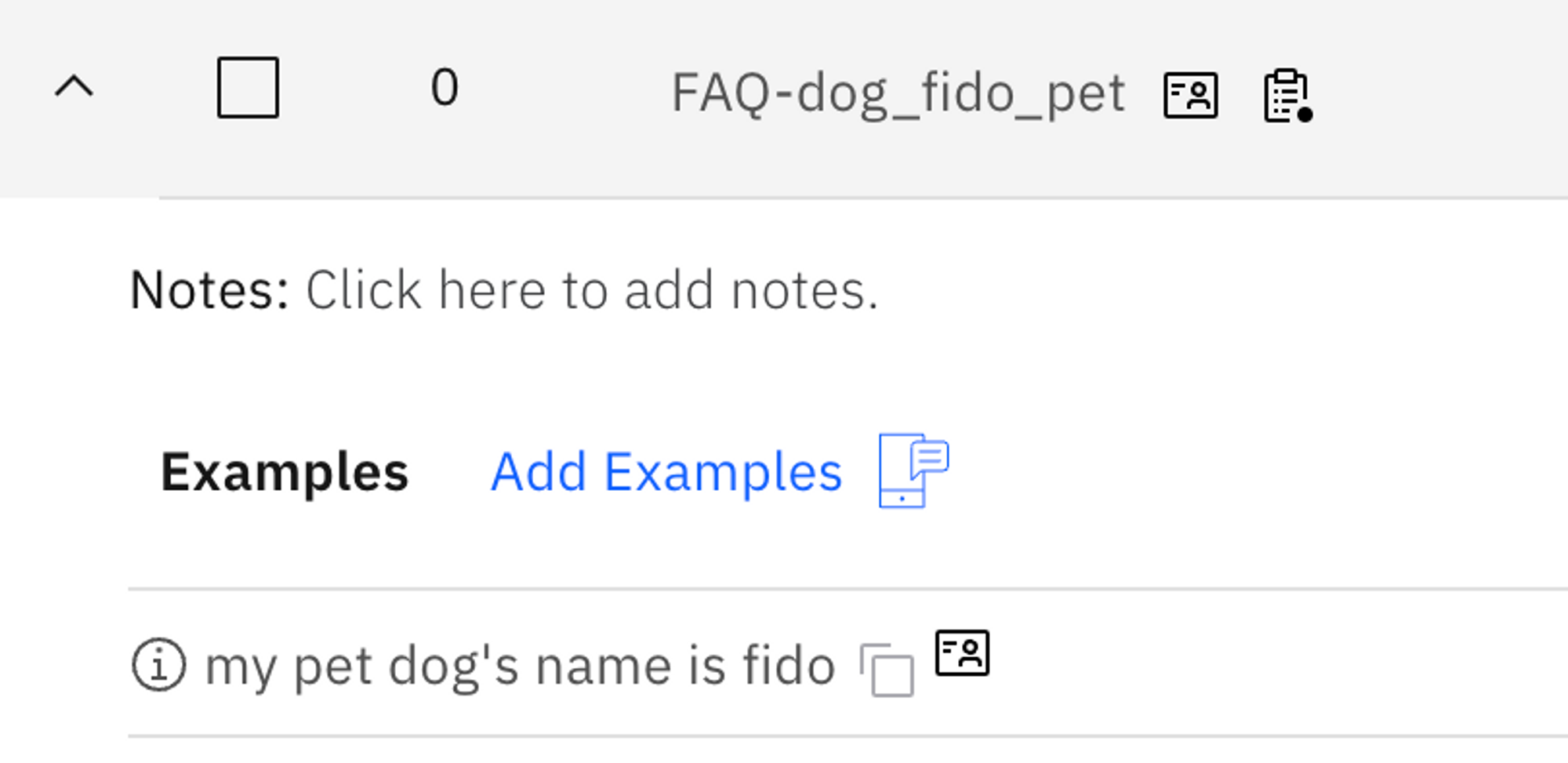
You can also make NeuralSeek ignore certain PII by entering “No PII” to the element. For example, by setting the element as “No PII” with a given example sentence, NeuralSeek will not filter out the question even though it would contain an PII element:

Therefore, when asked about a similar question, notice how dog’s name is now visible as not a PII information:
The base reason to use this is that sometimes, NeuralSeek would mistake certain questions to be containing PII, even though the sentence may clearly not contain any such data. In that case, setting what not to consider as PII would be very helpful.
Round Trip Logging
What is it?
- Round-trip logging is a process that involves recording and storing all interactions between a user and a Virtual Agent. NeuralSeek supports receiving logs from Virtual Agents in order to monitor curated responses. This includes the user’s question, the Virtual Agent’s response, and any follow-up questions or clarifications.
Why is it important?
- The purpose of round-trip logging is to improve the Virtual Agent’s performance by alerting to content in the Virtual Agent that is likely out of date, because the source documentation has changed.
How does it work?
- The Source Virtual Agent is connected to NeuralSeek via the specific instructions per platform on the Integrate tab. Once connected, NeuralSeek will monitor for intents that are being used live in the Virtual Agent. Once per day NeuralSeek will search the connected KnowledgeBase and recompute the hash for the returned data. That hash will be compared to the hash of the answers stored, and if no match is found, an alert will be generated notifying that the source documentation has changed compared to the last Answer generation completed by the seek endpoint.
Semantic Analytics
What is it?
- NeuralSeek generates responses by directly utilizing content from corporate sources. In order to ensure transparency between the sources and answers, NeuralSeek reveals the specific origin of the words and phrases that are generated. Clarity is further achieved by employing semantic match scores. These scores compare the generated response with the ground truth documentation, providing a clear understanding of the alignment between the response and the meaning conveyed in source documents. This ensures accuracy and instills confidence in the reliability of the responses generated by NeuralSeek.

Why is it important?
- By being able to analyze how the answer generated would be originated from the actual facts given by the KnowledgeBase, users can analyze from which sources the responses actually originated from, and how much of the responses are directly coming from the knowledge versus how much of them are from LLM’s generated answer. This ensures accuracy and instills confidence in the reliability of the responses generated by NeuralSeek.
For example, NeuralSeek’s Seek will provide rich semantic analytics in terms of how well the response cover for the facts found in the KnowledgeBase (or cached generated answers) by color-coding the area of it in the response, visually linking it to the sources, and providing semantic analysis result to explain the key reasons behind the semantic match score given.

How does it work?
- When NeuralSeek receives a question, it will first try to match for existing intents and answers, it will also try to search the underlying corporate KnowledgeBase and return any relevant passages from a number of sources. NeuralSeek will then either use these answers as-is directly, or use parts of the information to form a response using LLM’s generative AI capability.
Configuring Semantic Analytics
Configuration option for Semantic analysis is found under Configure > Confidence & Warning Thresholds . The semantic score model is enabled by default, but you can also disable it. You can also enable whether the semantic analysis should be used for confidence, and for reranking the search results from the knowledge base according to how much they semantically match. There are also sections for controlling how the analysis can apply penalties for missing key terms, search terms, or how frequent the sources are jumped (fragmented in the generated answer).
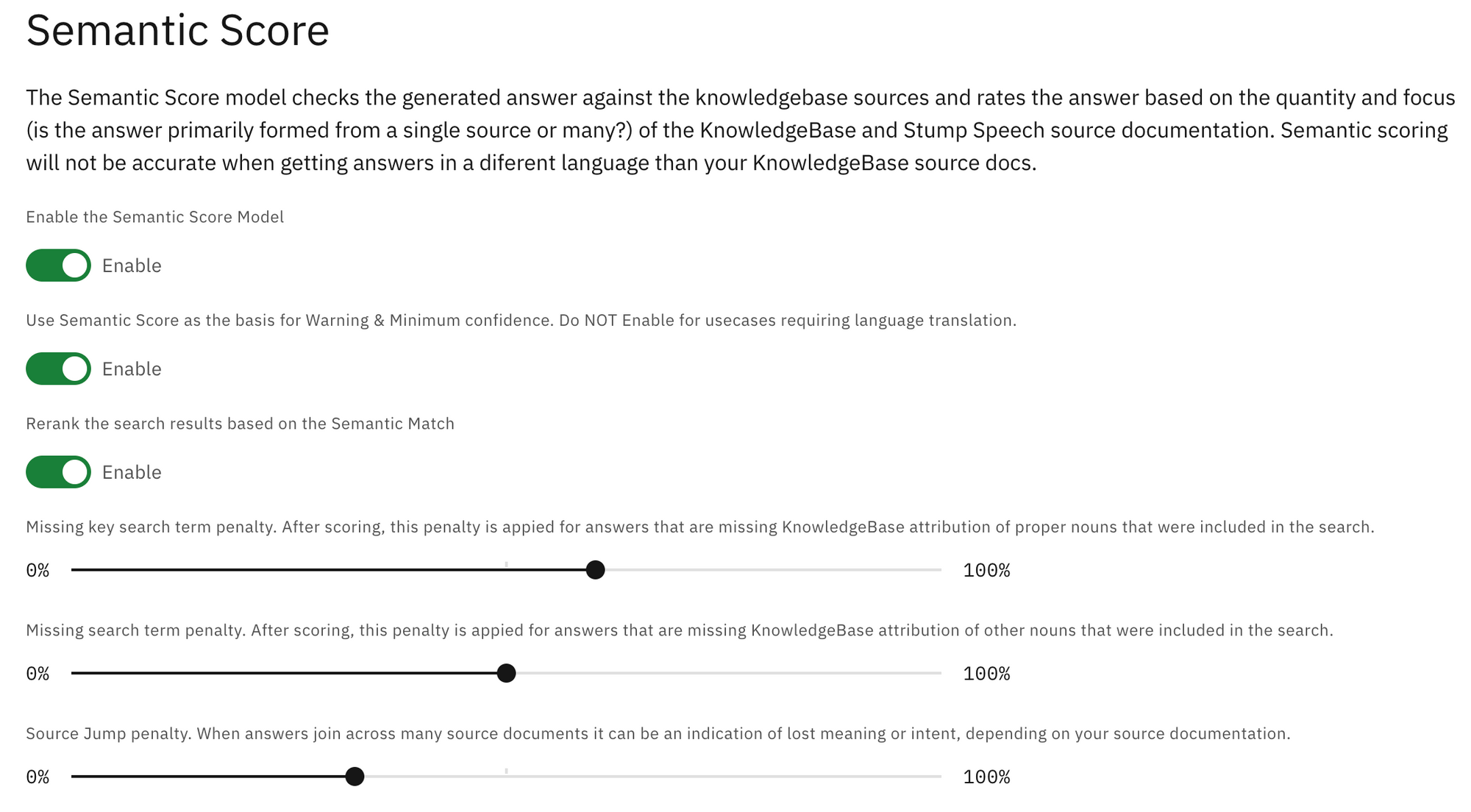
❓ How re-ranking the search result using semantic analysis can be helpful? Having an option to re-rank the resulting KnowledgeBase search results can ensure the list of search results to appear in the order that corresponds better to the answer provided. That is because sometimes the search results returned from the KnowledgeBase do not align perfectly with the answer, and thus the provided URL of the resulting document can be misleading.
Using Semantic Analysis
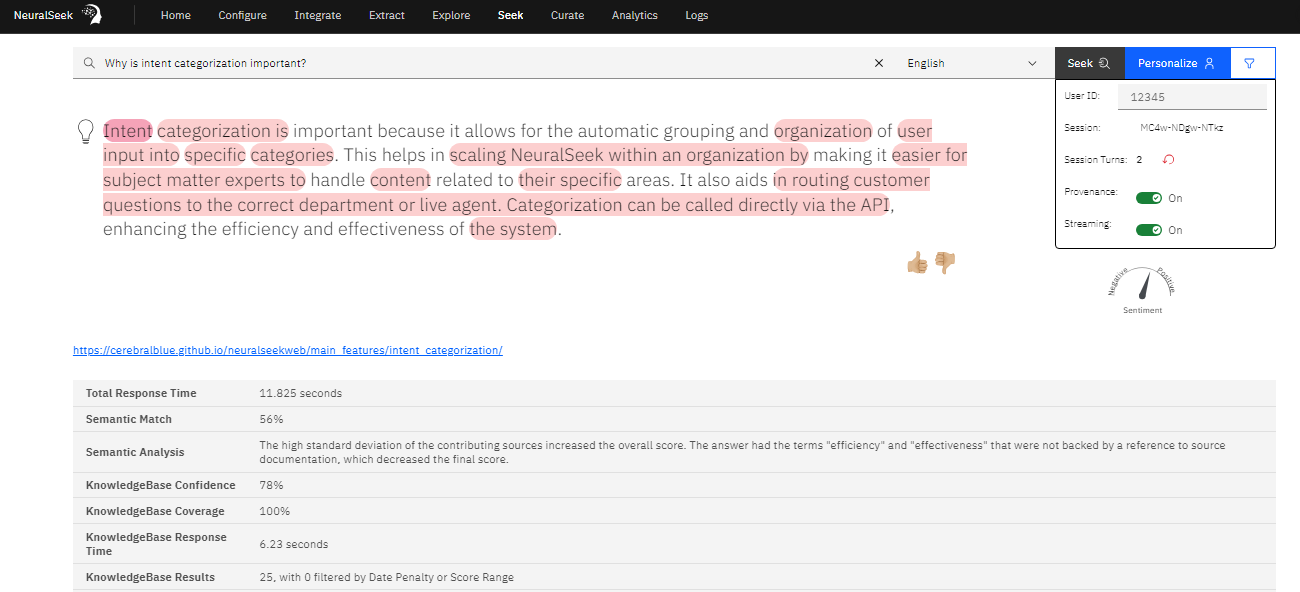
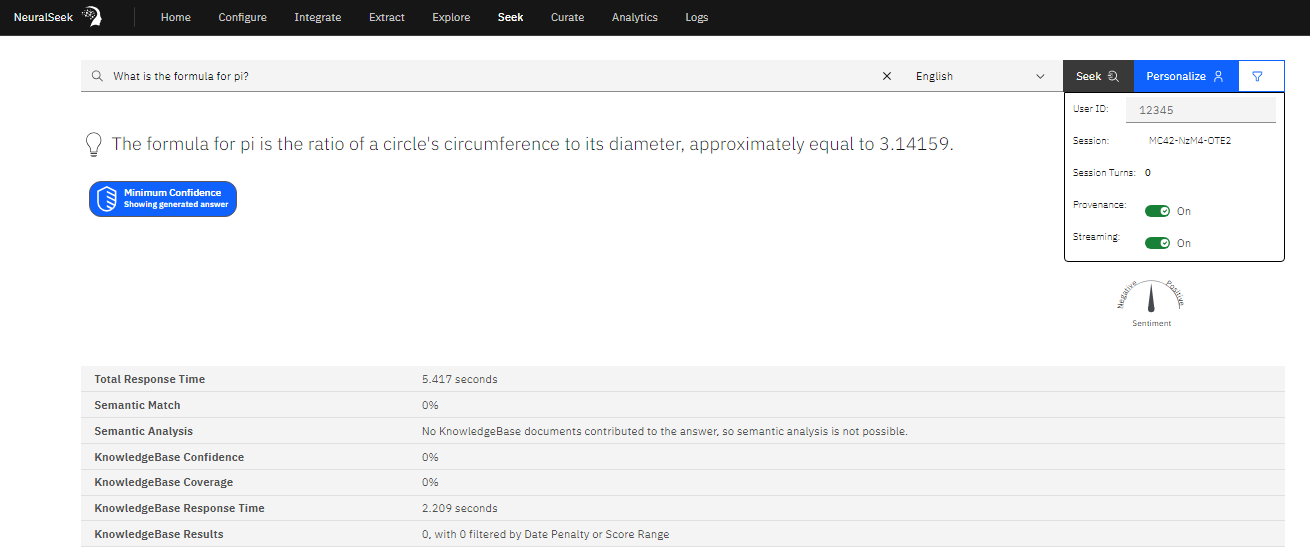
In the ‘Seek’ tab of NeuralSeek, you can provide a question, and be given an answer from NeuralSeek. When enabling the ‘Provenance’, this will give you the color-coded portion of the response that were directly originated from those results.

Below the answer, you will see some of the key insights related to the answer, such as Semantic Match score (in %), Semantic Analysis, as well as results coming from KnowledgeBase in terms of KB Confidence, KB Coverage, KB Response Time, and KB Results.

Semantic Match % is the overall match ‘score’ that indicates how much NeuralSeek believes that the responses are well aligned with the underlying ground truth (from KnowledgeBase). The higher the % is, the more accurate and relevant the answer is based on the truth.
Semantic Analysis explains why NeuralSeek calculated the matching score given in a way that is easy for users to understand. By reading this summary, users are given a good understanding why the answer was given either a high or low score.
Knowledge confidence, coverage, response time, and results are all coming from the KnowledgeBase itself. These percentages indicate the level of confidence and coverage, signifying the extent to which the KnowledgeBase believes the retrieved sources are relevant to the provided question.

KnowledgeBase contexts are the ‘snippets’ of sources from the KnowledgeBase, based on the relevance of what it found within its data. Clicking one of them would reveal the found passage, and the color code matching that of the generated answer would be used to highlight the parts that were used.

Lastly, the stump speech that is defined in NeuralSeek’s configuration is shown and color-coded based on how much of it was used in the answer.

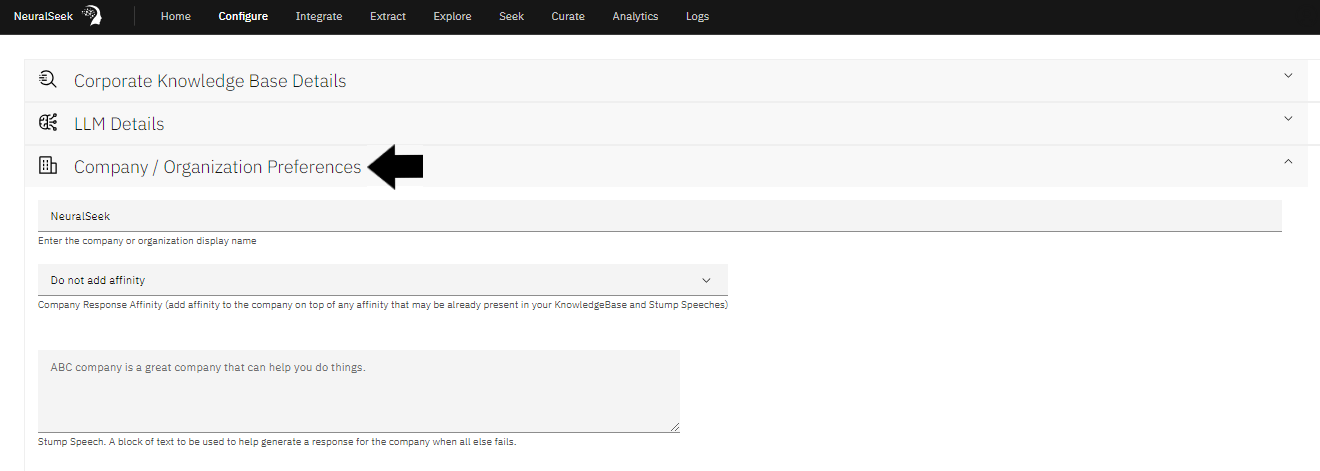
If you are wondering where the Stump Speech is stored, you can find it in Configure > Company / Organization Preferences section:
Setting the Date Penalty or Score Range
The resulting KnowledgeBase result does get affected by the configuration that you set for the corporate KnowledgeBase you are using with NeuralSeek. You can find these settings in Configure > Corporate KnowledgeBase Details section:

- Document score range dictates the range of possible ‘relevance scores’ that it will return as the result. For example, if the score range is 80%, the results will be of relevance score higher than 20% and equal or lower than 100%. If the score range is 20%, the relevancy score range would then be anything between 80% ~ 100%, respectively.
- Document Date Penalty, if specified higher than 0%, will start to impose penalty scores to reduce the relevancy based on how old the information is coming from. KnowledgeBase will try to find any time related information in the document and would reduce the score based on how old the time is, relative to current time.

When the results say, '4 filtered by date penalty or score range', it means these settings came into play when retrieving relevant information from the KnowledgeBase.
Examples of Semantic Analysis
High score example

Medium score example
Low score example
Sentiment Analysis
What is it?
- NeuralSeek's sentiment analysis is a feature that allows users to analyze the sentiment or emotional tone of a piece of text. It can determine whether the sentiment expressed in the text is positive, negative, or neutral. NeuralSeek's sentiment analysis is based on advanced natural language processing techniques and can provide valuable insights for businesses and organizations.
Why is it important?
- By being able to detect whether a user is negative or positive about certain questions, you can let the virtual agent use this information to provide more tailored services. For example, for a user who expresses negative sentiment, virtual agents might forward the session to human agents or assign higher priority so that more attention could be provided.
How does it work?
- NeuralSeek will run sentiment analysis on the user’s input text. Sentiment is returned as an integer between zero (0) and nine (9), with zero (0) being the most negative, nine (9) being the most positive, and five (5) being neutral.
Sentiment Analysis REST API
When using REST API, for example, providing negative comments could trigger a low sentiment analysis score.
{
"question": "I don't like NeuralSeek",
"context": {},
"user_session": {
"metadata": {
"user_id": "string"
},
"system": {
"session_id": "string"
}
},
Would yield a response with low sentiment score:
{
"answer": "String i'm sorry to hear that you don't like NeuralSeek. If you have any specific concerns or feedback, please let me know and I'll do my best to assist you.",
"cachedResult": false,
"langCode": "string",
"sentiment": 3,
"totalCount": 9,
"KBscore": 3,
"score": 3,
"url": "https://neuralseek.com/faq",
"document": "FAQ - NeuralSeek",
"kbTime": 454,
"kbCoverage": 24,
"time": 2688
}
Notice the sentiment score of 3, which is in the low range of 0 - 10. On the other hand, if you express a positive sentiment as such:
{
"question": "I really love NeuralSeek. It's the best software in the world.",
"context": {},
"user_session": {
"metadata": {
"user_id": "string"
},
"system": {
"session_id": "string"
}
},
The response will have a higher sentiment score:
{
"answer": "Thank you for sharing your positive feedback about NeuralSeek. I cannot have personal opinions, but I'm glad to hear that you find NeuralSeek to be the best software in the world.",
"cachedResult": false,
"langCode": "string",
"sentiment": 9,
"totalCount": 9,
"KBscore": 15,
"score": 15,
"url": "https://neuralseek.com/faq",
"document": "FAQ - NeuralSeek",
"kbTime": 5385,
"kbCoverage": 8,
"time": 7094
}
Table Understanding
What is it?
- Table Extraction, also known as
Table understanding, pre-processes your documents to extract and parse table data into a format suitable for conversational queries. Since this preparation process is both costly and time-consuming, this feature is opt-in and will consume 1 seek query for every table preprocessed. Also, it should be noted that Web Crawl Collections are not eligible for table understanding, as the recrawl interval will cause excessive computing usage. Table preparation time takes several minutes per page.
Why is it important?
- Being able to understand data in tabular structure in documents and generating answers is an important capability for NeuralSeek in order to better find the relevant data for answering.
How does it work?
- To find table extraction, open up your instance of NeuralSeek and head over to the
Configure. - Select Table understanding
⚠️ Note for users of lite/trial plans - to be able to access and use this feature you will have to contact [email protected] with details of your opportunity and use case to be eligible.
-
Once you have everything set, go over to
Watson Discovery, and if you don’t already,create a project and import a pdf filethat contains some tables. -
Once you have the project copy the API information and go back to the
Configurein NeuralSeek. Scroll down to Table Understanding, paste the project id, hit save, and proceed to theSeektab. -
With everything set, ask some questions related to the data inside the table in the PDF file.
What were the GHG emissions for business travel in 2021?
You can also ask questions about a specific place or name and if there are multiple tables with data, NeuralSeek will take from each table and provide you with everything.
Multimodal LLMs in mAIstro
What is it?
Multimodal capabilities in large language models (LLMs) refer to their ability to process and generate content across multiple modalities, such as text, images, and even audio. This allows LLMs to understand and interact with the world in a more holistic and natural way, going beyond the traditional text-based interactions.
Why is it important?
Multimodal capabilities are crucial for a wide range of applications, particularly in areas like visual question answering, image captioning, and image-to-text generation. These capabilities enable LLMs to understand and reason about the world in a more comprehensive manner, allowing for more intuitive and user-friendly interactions.
How does it work?
Multimodal LLMs typically leverage techniques like transfer learning, where the model is first trained on a large corpus of text data, and then fine-tuned on datasets that combine text and images. This allows the model to learn the relationships between visual and textual information, enabling it to generate relevant and coherent responses to queries that involve both modalities.
Steps to Configure the LLM
To begin, navigate to the Configure tab and locate the LLM Details section.
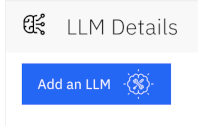
Click on "Add an LLM" and choose a model that can process images, such as OpenAI GPT-4o.
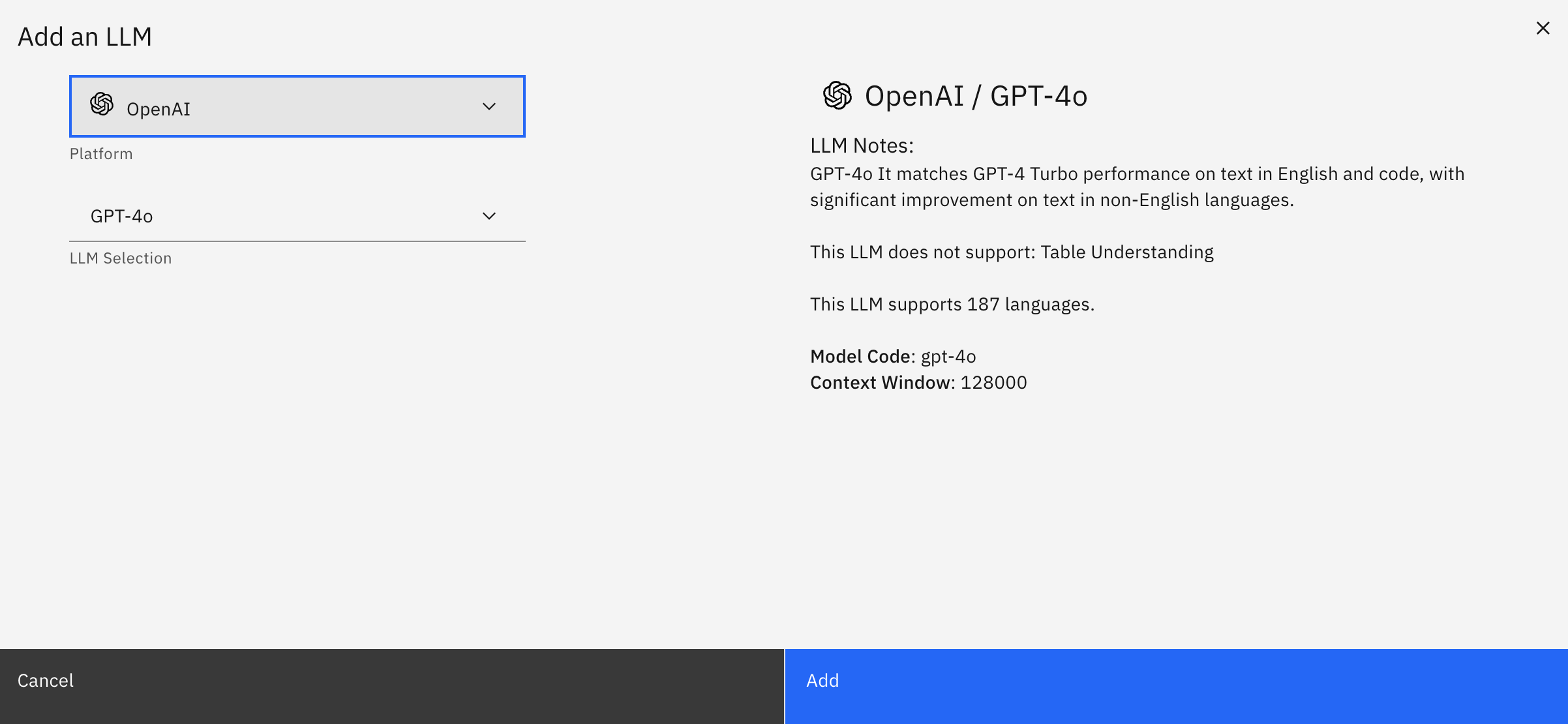
Once selected, add the model and enter the necessary connection details, which, for GPT-4o, would be the API Key.
Test the connection by clicking the Test button and ensure the button turns green, indicating a successful connection.
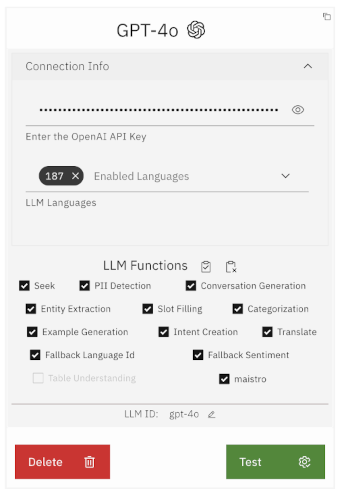
Save the configuration and provide a meaningful name for the version.
Steps to Process an Image
Next, switch to the Maistro tab to upload an image. Use the left side pane to search for "Upload data" and then select "Upload file" under that section.
After selecting the local file, a local document node will be created. Set the body of this node like this:
<< name: img, prompt: true, desc: Enter image file name >>
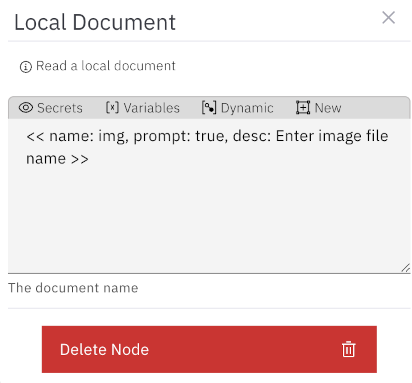
If you plan to use this image for different purposes, it’s best to set it as a variable. Add a set variable node to the right of the local document node and give the variable a descriptive name.
Below these nodes, add a send to LLM node. For the prompt, you can use:
What is this a picture of?
For the image, reference the variable you defined earlier:
<< name: img, prompt:false >>
And the node should be end up like this:

Select an LLM that supports reading images, such as GPT-4o.
Press the Evaluate button. You will be prompted to enter the name of the image file you want to process, including its file extension. Once entered, the setup will allow Maistro to describe the image.

Note
This is a basic example, but you can expand on this logic to achieve more complex procedures.